My experiments with RoPE
A companion experiment to my Positional Encoding posts in The Gradient Descent through Transformers series. Lab notes — what happens when a fifteen-minute confirmation experiment refuses to confirm.
The plan was modest: a fifteen-minute experiment for my positional encoding series. Four PE methods, one tiny test bench, plot the results, write a takeaway. The textbook conclusion was supposed to write itself — ALiBi and RoPE both extrapolate cleanly to longer sequences, sinusoidal and learned methods collapse outside their training range. Run, plot, ship. But — surprise, surprise.
RoPE collapsed too.
From 100% accuracy at training length to 33% at 8× longer sequences. And RoPE is the positional encoding every frontier LLM in 2026 runs on — Llama, Mistral, Qwen, DeepSeek, Gemma. Its whole reputation is "the modern standard for length generalization." Either I'd implemented it wrong, or the textbook story was missing something.
The implementation was fine. What followed was three more experiments, a research paper that documented exactly what I was seeing, and a chronological tour of how production LLMs have been quietly patching this problem for years. The picture that emerged is much more nuanced than any tutorial I've read on the subject.
These are my notes from that investigation.
The Test Bench
I needed a synthetic task that isolates positional encoding behavior — no language to model, no content patterns to lean on. Just position.
The task: predict-previous-token. Given a sequence of random tokens [t_0, t_1, …, t_{n-1}], the model has to output [_, t_0, t_1, …, t_{n-2}] — at each position, predict the previous token. Position 0 has no previous token, so its loss is masked.
Why this design? With random tokens, content carries no signal. To predict input[i-1], the model must know its own position relative to the rest of the sequence. There's literally no other way. So whatever generalization the model achieves comes from the positional encoding alone.
I trained four tiny transformers, identical except for the PE method:
- Sinusoidal: the original Vaswani et al. (2017) formula, added to token embeddings before the first layer
- Learned: a
nn.Embedding(max_len, d_model)lookup, added the same way (BERT/GPT-2 style) - ALiBi: a fixed linear penalty
−m · |i − j|added to attention scores, with one slope per head (Press et al., 2022) - RoPE: rotation matrices applied to Q and K vectors inside attention (Su et al., 2021)
Every other architectural detail held constant: 2 layers, 64 hidden, 2 heads, RMSNorm, SwiGLU, causal masking. Trained on length-64 sequences for 500 steps, evaluated at lengths 64, 128, 256, and 512.
Each variant converged to near-zero loss at training length — so they all can learn the task. The interesting question was what would happen past 64.
The Surprise
Here's what came out of evaluation:
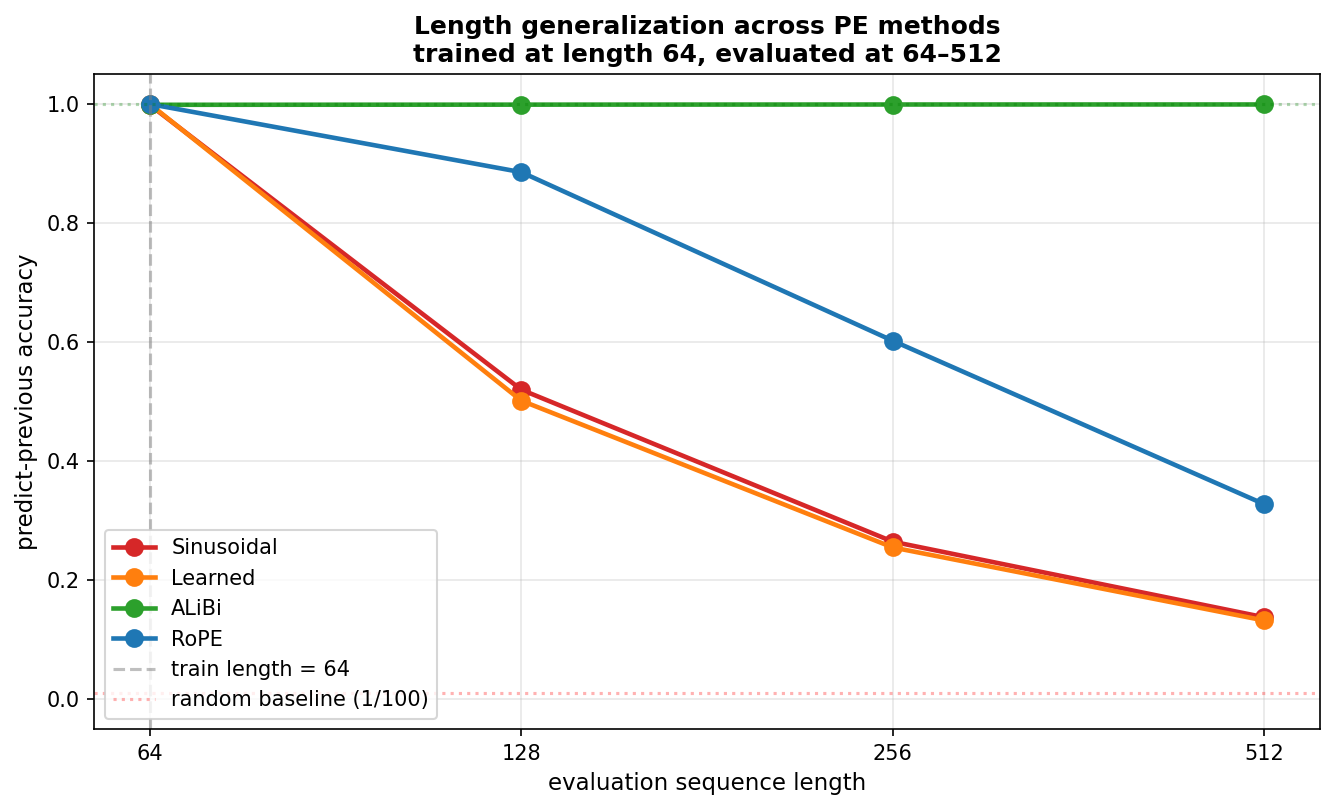
| method | L=64 | L=128 | L=256 | L=512 |
|---|---|---|---|---|
| Sinusoidal | 0.998 | 0.520 | 0.265 | 0.138 |
| Learned | 1.000 | 0.502 | 0.256 | 0.133 |
| ALiBi | 0.999 | 0.999 | 0.999 | 0.999 |
| RoPE | 1.000 | 0.886 | 0.602 | 0.328 |
Length generalization across PE methods — ALiBi flat at 0.999, RoPE degrading from 1.0 to 0.328, absolute methods collapsing
Two of these results matched my expectations:
- Absolute methods collapse. Sinusoidal and learned PE crash to near-random by L=512. They have no entry (learned) or untrained behavior (sinusoidal) at positions past training. Expected.
- ALiBi extrapolates perfectly. Identical accuracy at every length. Beautiful, expected.
But the RoPE column was wrong. Not catastrophically wrong — RoPE clearly does better than absolute methods, and the degradation is graceful rather than abrupt. But "graceful degradation" is not what every blog post and tutorial promised. RoPE is supposed to be the gold standard for length generalization. From 1.000 at training length to 0.328 at 8× the training length is not gold-standard behavior.
My first thought was that I'd implemented RoPE wrong.
Was it a bug?
RoPE's central mathematical claim is that the dot product of rotated Q and rotated K depends only on their relative offset, not on their absolute positions. If my implementation broke that property, all bets were off.
So I tested it directly:
torch.manual_seed(0)
d_head = 32
q_base = torch.randn(d_head)
k_base = torch.randn(d_head)
def score_at(pos_q, pos_k):
"""Place q at pos_q, k at pos_k; rotate; return their dot product."""
seq_len = max(pos_q, pos_k) + 1
q_full = torch.zeros(1, 1, seq_len, d_head)
k_full = torch.zeros(1, 1, seq_len, d_head)
q_full[0, 0, pos_q] = q_base
k_full[0, 0, pos_k] = k_base
q_rot = apply_rope(q_full)
k_rot = apply_rope(k_full)
return (q_rot[0, 0, pos_q] * k_rot[0, 0, pos_k]).sum().item()If RoPE is mathematically correct, then four pairs that all share the same offset −1 should produce identical scores, regardless of where they sit in the sequence:
score(5, 4) = -3.040400
score(100, 99) = -3.040401
score(500, 499) = -3.040397
score(800, 799) = -3.040404
Identical to five decimal places. The tiny differences are float32 precision. RoPE was working exactly as designed.
So the implementation is correct. The math holds. And yet the model still degrades. That meant something more interesting was going on at a level I didn't yet understand.
Why "score consistency" isn't enough
The piece I was missing is what softmax actually requires for clean attention.
When the model is at position 100 and wants to predict the previous token, the attention layer's job is to produce a probability distribution that puts almost all the weight on position 99. That's not just "give offset −1 the highest score." It's "give offset −1 a score that dominates the softmax over all available positions."
Softmax of [s_0, s_1, …, s_n] produces:
To make w_99 ≈ 1, you need both: s_99 to be high and every other s_j to be much lower. If 99 of the scores are roughly 0 and one is +5, you'd think the +5 wins easily. But:
e^5 ≈ 148
sum = 148 + 99 × 1 = 247
weight on s_99 = 148/247 ≈ 0.60
The "winner" gets only 60% of the mass. With more competitors at score 0, it gets diluted further. To dominate, you need the winning score to be much higher and the losers to be much lower — exponentials are unforgiving.
Now here's the key insight: at training length 64, the model competed offset −1 against offsets −2 through −63. It learned Q and K projections that make the score for offset −1 higher than the rest, and it learned to make the rest low (negative). For 63 competitors held at meaningfully negative scores, the softmax cleanly resolves. Done.
At evaluation length 512, position 500 sees offsets −1 through −500. RoPE's consistency guarantees:
- The score at offset
−1is the same as during training: high. ✓ - The scores at offsets
−2through−63are the same as during training: low. ✓ - The scores at offsets
−64through−500are... whatever the Q and K projections happen to produce when paired with rotation matrices the model never explicitly competed against.
The model didn't shape those scores during training. They're a side-effect of the geometry — uncontrolled, distributed roughly around 0. With 437 unseen offsets each contributing roughly e^0 = 1 to the softmax denominator, the math breaks:
weight on offset -1 ≈ 148 / (148 + 62 × e^(-3) + 437 × e^0)
≈ 148 / (148 + 3 + 437)
≈ 148 / 588
≈ 0.25
A back-of-envelope estimate that drops from ~98% confidence to ~25% as length goes from 64 to 512 — uncomfortably close to what the experiment actually showed.
The deeper distinction
This is what RoPE and ALiBi actually differ on, even though both are called "relative" methods:
| What it provides | What it doesn't | |
|---|---|---|
| RoPE | Consistency — same offset → same score across positions | Decay — no built-in suppression of distant tokens |
| ALiBi | Decay — far offsets get an unconditional `−m· | i−j |
ALiBi's penalty is the killer feature. At position 500 looking at offset −500, the bias contribution is −250 (with slope 0.5). The total score is something like Q·K − 250. After softmax, e^(−250) is so close to zero that the position contributes nothing — regardless of what the content score did. The locality is enforced by the formula itself, not learned.
For length generalization without any training tricks, decay is what matters. RoPE provides consistency, which only helps within the trained range.
Experiment 2: Real Language isn't random tokens
Once I had the explanation, I wanted to push on it. The issue with vanilla RoPE is that its score function is uncontrolled at unseen offsets. But that uncontrolled-ness only matters when there's nothing else to suppress those offsets.
In real text, nearby tokens are usually semantically related; far-apart tokens usually aren't. Consider:
"The cat sat on the mat. It was a sunny day. The mat was warm."
When predicting "warm", the model attends to "mat" (offset −1, semantically matched) much more than to "It" (offset −7) or "cat" (offset −10). And dramatically more than to a random token 5,000 positions earlier.
The Q · K dot product already contains "is this content relevant?" information. For semantically unrelated content, the dot product is small. So even without RoPE doing the suppression, the content channel naturally suppresses far attention.
This is the saving grace my synthetic experiment strips out. The hypothesis: if I add some content correlation to the synthetic task, RoPE's curve should flatten.
So I built a Markov chain version. Instead of fully random tokens, each token has a 30% probability of being the same as the previous one — a soft "locality bias" in the data itself, mimicking language's adjacency structure at a tiny scale.
I retrained all four PE methods on this data and re-evaluated. Here's what changed at the longer lengths:
| method | random L=512 | Markov L=512 | change |
|---|---|---|---|
| Sinusoidal | 0.138 | 0.178 | +0.040 |
| Learned | 0.133 | 0.163 | +0.030 |
| ALiBi | 0.999 | 0.998 | unchanged (already at ceiling) |
| RoPE | 0.328 | 0.550 | +0.222 |
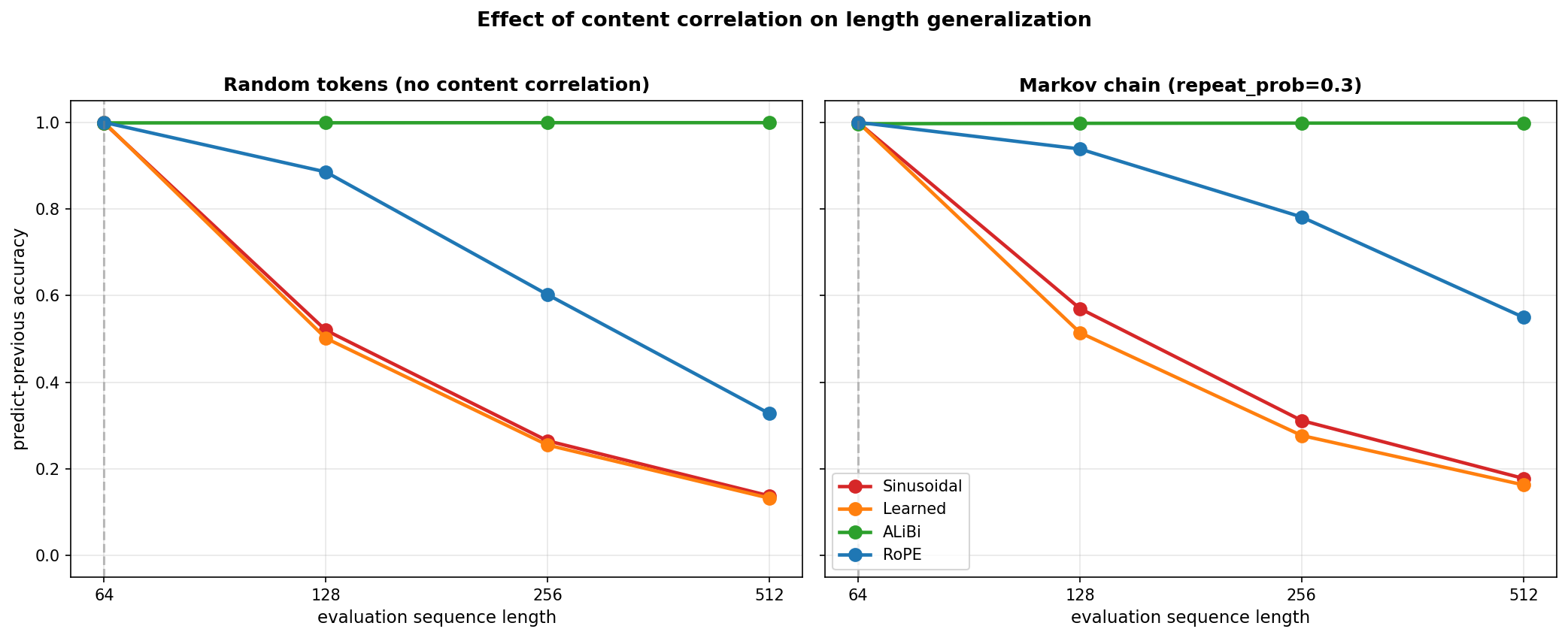 Side-by-side comparison: random tokens vs Markov chain. RoPE's curve flattens dramatically with content correlation while ALiBi stays perfect and absolute methods barely move.
Side-by-side comparison: random tokens vs Markov chain. RoPE's curve flattens dramatically with content correlation while ALiBi stays perfect and absolute methods barely move.
The headline: RoPE's accuracy at L=512 jumped by 22 points with content correlation. The L=256 jump is similar (0.602 → 0.781). RoPE benefits enormously from the content channel doing the suppression work that its position channel can't.
The absolute methods improve only marginally — content can't fix "no information at all at unseen positions." ALiBi was already at ceiling, so there was no room to improve.
This was a strong empirical confirmation of the mechanism. Real language gives RoPE a free decay structure via the content channel. Synthetic random-token tasks strip it away and expose RoPE's lack of an explicit decay prior. With even a modest 30% Markov chain, the gap between RoPE and ALiBi shrinks dramatically. With richer correlation structure (real text has long-range syntactic and semantic dependencies, not just 1-step Markov), the gap shrinks further.
Experiment 3: Patching RoPE myself
The Markov result told me content correlation rescues RoPE — that's one fix. But there's also a parametric fix that doesn't need richer data: rescale RoPE's frequencies so that unseen positions look like trained ones.
NTK-aware scaling (bloc97, 2023) is the simplest version. Rescale the RoPE frequency base θ by scale^(d_head / (d_head − 2)), where scale = eval_len / train_len. The high-frequency dimensions get more compression, low-frequency dimensions less. The whole change is a couple of lines.
Crucially, this is applied at inference time only — no retraining. I took the same vanilla-RoPE-trained model and just swapped the rotation logic. If RoPE's degradation is really about "unseen offsets having uncontrolled scores," then reshaping those offsets to look like trained ones should recover most of the lost accuracy.
It does:
| L | Vanilla RoPE | + NTK | ALiBi |
|---|---|---|---|
| 64 | 1.000 | 1.000 | 0.999 |
| 128 | 0.886 | 0.999 | 0.999 |
| 256 | 0.602 | 0.994 | 0.999 |
| 512 | 0.328 | 0.770 | 0.999 |
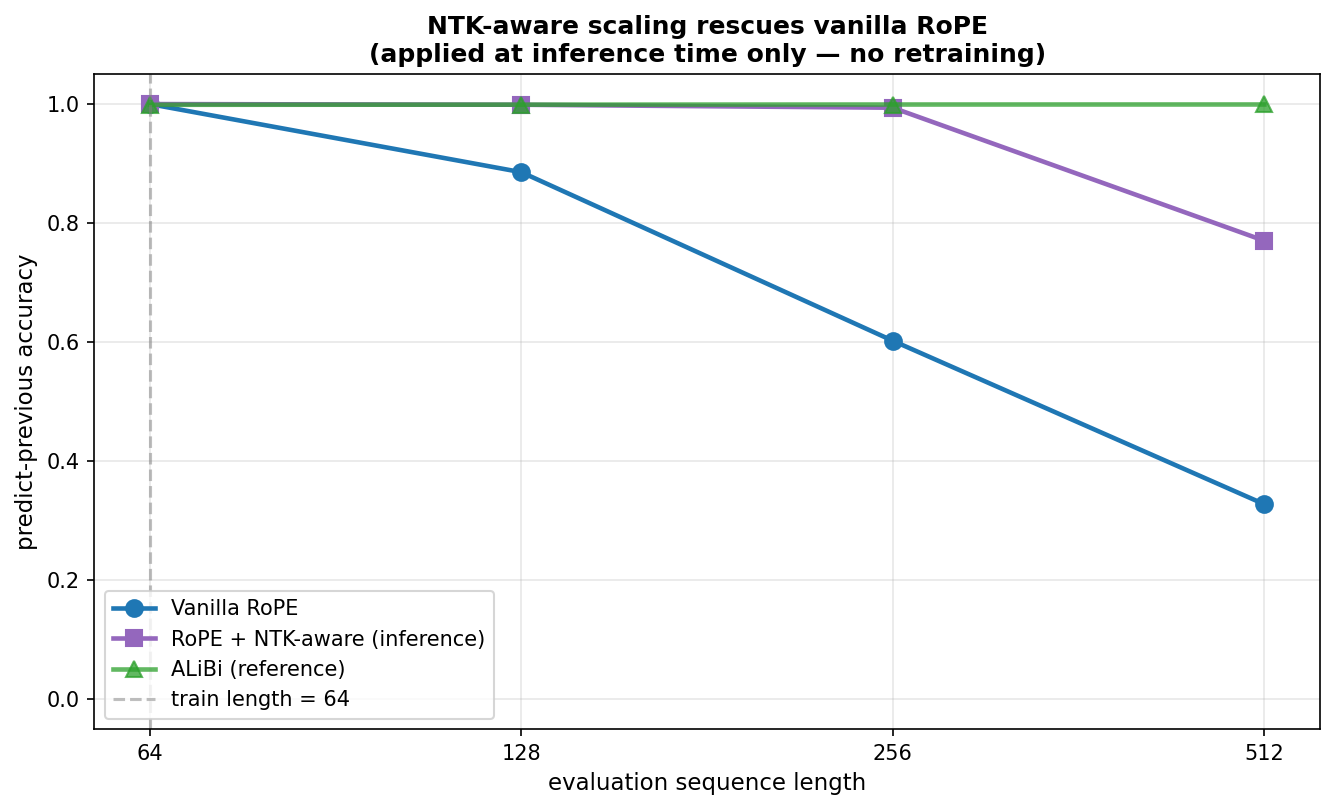 NTK-aware scaling closes most of the gap between vanilla RoPE and ALiBi. At 2× and 4× extension the recovery is essentially complete; at 8× it's partial.
NTK-aware scaling closes most of the gap between vanilla RoPE and ALiBi. At 2× and 4× extension the recovery is essentially complete; at 8× it's partial.
At 2× and 4× extension, NTK essentially closes the gap to ALiBi entirely. At 8× extension, it recovers about half the lost ground but doesn't fully match. A one-line change at inference time, no retraining, no extra parameters — and most of the gap closes.
That left me with a clean picture from three experiments:
- Vanilla RoPE on random tokens: collapses past training length
- Vanilla RoPE on Markov-correlated tokens: degrades much less (content rescues partially)
- Vanilla RoPE + NTK at inference time: degrades very little (parametric fix rescues mostly)
So the question that originally surprised me — "why does RoPE collapse?" — turned into a more interesting one: how much of this is documented? Am I rediscovering well-known things?
Realization: I'm not the first to notice this
After running these three experiments, I went looking at the literature systematically. The first thing I found was the rigorous benchmark study I'd missed.
Kazemnejad et al. (2023), "The Impact of Positional Encoding on Length Generalization in Transformers", is a head-to-head benchmark of positional encoding methods — sinusoidal, learned, T5 bias, ALiBi, RoPE, and NoPE (no positional encoding at all, just relying on the causal mask) — across reasoning and synthetic tasks at varying lengths.
Their headline finding: RoPE consistently underperforms ALiBi on length generalization. It even underperforms NoPE. A method that uses no explicit positional encoding at all — just the causal mask leaking position info implicitly — beats RoPE on length-extrapolation benchmarks.
This was unexpected. RoPE's reputation in 2025–2026 is "the modern standard for length generalization." But the rigorous benchmark says otherwise — at least for vanilla RoPE without any extension tricks.
That matched what I was seeing in my own toy experiment exactly. The collapse from 1.000 to 0.328 at 8× extension wasn't a quirk of my setup — it was the documented behavior. The specific quantitative numbers depend on the architecture, training, and task, but the qualitative pattern (vanilla RoPE underperforming ALiBi on synthetic length generalization) is well-established.
That left me with the actual interesting question: if vanilla RoPE underperforms on benchmarks, why does every production LLM use it?
What production actually does
If you go look at the configs of frontier LLMs in 2026, the answer is: they do use RoPE — but never vanilla RoPE. Every production deployment patches RoPE's extrapolation problem. The patches differ across models, and they evolved chronologically as the field figured out what works.
The chronological evolution
RoPE original (Su et al., 2021). The paper introduces rotary position embeddings — Q and K vectors get rotated by their absolute positions, and the dot product naturally depends only on relative offset. The paper demonstrates strong in-distribution performance but doesn't strongly test length extrapolation past training context.
Position Interpolation (Chen et al., Meta, June 2023). The first paper to publicly document the failure mode I observed. Their report: extending Llama-7B's context from 2K to 4K via vanilla RoPE causes perplexity to explode. Their fix: rescale all positions to fit inside the trained range. If the model was trained at 2K and you want 4K, divide all positions by 2 before applying RoPE. The model thinks it's still operating in [0, 2K]. Surprisingly effective, but compresses high-frequency positional info.
NTK-Aware Scaling (bloc97, Reddit, July 2023). A community-developed alternative to PI. Instead of rescaling all positions uniformly (which compresses high-frequency dimensions and loses fine-grained position info), NTK-aware scales the RoPE base θ non-uniformly — high-frequency dimensions get more compression, low-frequency dimensions less. The intuition comes from neural tangent kernel theory; the result preserves fine-grained positional info better than under PI. This is the patch I implemented in Experiment 3.
YaRN (Peng et al., 2023). Refines NTK-aware further. Adds an attention scaling correction (since rescaling θ also affects the attention magnitude) and tunes per-frequency-band rather than per-dimension. The variant DeepSeek V3 and Qwen 2.5+ actually ship.
LongRoPE (Ding et al., 2024). Pushes context windows to 2M+ tokens. Uses evolutionary search to find optimal per-frequency rescaling factors instead of relying on a single closed-form scheme. State of the art for extreme context extension.
The pattern: every two years, a new paper comes out fixing some failure mode of the previous fix. The whole research program exists because vanilla RoPE doesn't extrapolate. If it did, none of these papers would.
What models actually use today
I went and checked the actual config.json files of recent frontier models. Here's what they do:
DeepSeek V3 (December 2024). The most aggressive setup I found. From its config:
"rope_theta": 10000,
"rope_scaling": {
"type": "yarn",
"factor": 40,
"original_max_position_embeddings": 4096,
"beta_fast": 32,
"beta_slow": 1
}DeepSeek trains at 4K context and uses YaRN with scaling factor 40 to extend to 163,840 tokens. It also wraps RoPE inside MLA (Multi-Latent Attention) with a "decoupled RoPE" design — a separate 64-dim head specifically for position info, kept distinct from the 128-dim compressed latent. Three orthogonal length-related techniques stacked together.
Qwen 2.5/3. Trains at 32K, uses YaRN with factor 4 to extend to 131K. More conservative scaling than DeepSeek but the same fundamental pattern — train short, scale long.
Llama 3. Different approach. Sets rope_theta = 500_000 (50× the original 10K base) and trains at high context natively. The larger base "stretches" RoPE's rotation periods, helping long-context modeling without explicit inference-time scaling. Llama 3.1 added a custom YaRN-like scheme for 128K context.
Gemma 3. Different again. Uses RoPE everywhere but pairs it with a hybrid attention pattern — 5 sliding-window-attention layers for every 1 full-attention layer. The architectural constraint (most layers can only attend within a small window) does the locality work that ALiBi's bias would do. Each layer type uses its own RoPE base θ.
What's striking: all four use RoPE. None switched to ALiBi. None use vanilla RoPE either. Everyone patches the extrapolation problem in their own way:
- DeepSeek / Qwen: parameter scaling at inference (YaRN)
- Llama: training-time θ tuning
- Gemma: architectural locality (sliding windows)
Vanilla RoPE doesn't appear in any production deployment. The Kazemnejad finding ("vanilla RoPE underperforms") is the empirical cost of not applying these patches. The universal patching is the industry's collective response.
So why did RoPE win?
Putting it all together, here's what I think the actual answer is to the puzzle that drove the investigation.
RoPE wins not because it's the best at extrapolation. It's not. RoPE wins because it balances four competing concerns better than the alternatives:
1. In-distribution quality. Inside the training context, RoPE's content × position interaction (rotating Q and K rather than just adding biases) gives it a richer score function than ALiBi's additive bias. Content and position interact multiplicatively, which matters for tasks that need content-aware attention patterns at multiple scales.
2. Long-range expressiveness. ALiBi has a hard locality prior. The bias −m·|i−j| strictly increases with distance — the model literally cannot strongly attend to a token 5,000 positions away because the bias overwhelms any content signal. This is fine for many tasks but destructive for long-context retrieval, in-context learning over many examples, and code completion across large files. RoPE has no such cap.
3. Composability with extension tricks. RoPE has tunable parameters — the frequency base θ, the per-dimension rotation rates — that can be massaged for length extension. PI, NTK-aware, YaRN, LongRoPE all exploit this. ALiBi has nothing analogous to scale. Once you've trained ALiBi at a given slope, the only way to extend its effective range is to retrain.
4. Content-correlation forgiveness. Real language has natural locality from content. The decay prior RoPE lacks is partly recovered by Q·K being small for unrelated content. ALiBi's decay is redundant in this regime; RoPE's lack of decay is masked. My Markov experiment is a small-scale demonstration of this.
ALiBi wins on length generalization in a vacuum. RoPE wins on the practical combination of in-distribution quality, long-range expressiveness, patch-ability, and content-correlation forgiveness — once you accept that production will always layer something like YaRN on top.
What this taught me about reading the literature
The slogan "RoPE generalizes" is, like most slogans, a compressed truth. With NTK-aware or YaRN scaling, RoPE generalizes very well — to 100K+ context windows that were unthinkable a few years ago. Without those tricks, vanilla RoPE generalizes worse than ALiBi, worse than NoPE on synthetic benchmarks. The slogan elides the patches.
This isn't unusual. Production-tested architectural choices in deep learning often have nuance that gets flattened in popularizations. The Kazemnejad benchmark was a corrective; the YaRN line of work is the field's response to the same observation. The blog post you read first ("RoPE is the best") and the rigorous benchmark paper you read second ("actually NoPE beats RoPE") are both telling true partial stories. Both can be right because they're answering different questions.
What I particularly liked about how this investigation unfolded: the experiments came before the literature search. I built the test bench expecting confirmation, found a discrepancy, debugged my way into a mechanistic explanation, ran two follow-up experiments that lined up with the explanation, and only then went looking for what others had documented. The literature confirmed what the experiments had already shown and slotted in cleanly.
The version of this where I'd read the Kazemnejad paper first and then run the experiment would have been less interesting. The result wouldn't have surprised me, the dig wouldn't have happened, the synthesis wouldn't have come together the same way. Build the experiment, then read the literature. A handful of GPU-minutes on a tiny synthetic task can falsify pop wisdom and reveal where the nuance actually lives. The version of "RoPE is the best for length generalization" that I would have casually believed gets undone by a single afternoon's worth of code.
If you take one thing from this post, take that.
Code
The full code for all three experiments lives in my ml-training-logs repo. The key files:
comparison.ipynb— the test bench: dataset, training loops, evaluation, plots, and both follow-up experiments (Markov chain and NTK-aware scaling)02_alibi_solution.ipynband03_rope_solution.ipynb— clean implementations of the PE methods../../common/mini_transformer.py— the swappable transformer used as the experiment vehicle
Everything runs on CPU in under a minute.
References
- Kazemnejad et al. (2023). The Impact of Positional Encoding on Length Generalization in Transformers. — The benchmark showing RoPE underperforming ALiBi (and NoPE).
- Chen et al. (2023). Extending Context Window of Large Language Models via Position Interpolation. — Meta's paper introducing PI, the first systematic patch for RoPE's extrapolation.
- bloc97 (2023). NTK-Aware Scaled RoPE. — The Reddit post introducing NTK-aware scaling.
- Peng et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models. — The successor to NTK-aware scaling, used by DeepSeek V3 and Qwen 2.5+.
- Ding et al. (2024). LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens. — Evolutionary search for per-frequency rescaling.
- Press et al. (2022). Train Short, Test Long: Attention with Linear Biases. — The ALiBi paper.
- Su et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. — The RoPE paper.
- Vaswani et al. (2017). Attention Is All You Need. — The transformer paper introducing sinusoidal positional encoding.
If you found this useful, the broader context lives in my blog series The Gradient Descent through Transformers — particularly Positional Encoding Part 1 and Part 2.