Papers, Annotated
Reading notes for papers I've worked through — the diagrams I wished existed, the derivations I had to redo, and the parts that took me longest to understand.
Annotated
May 13, 2026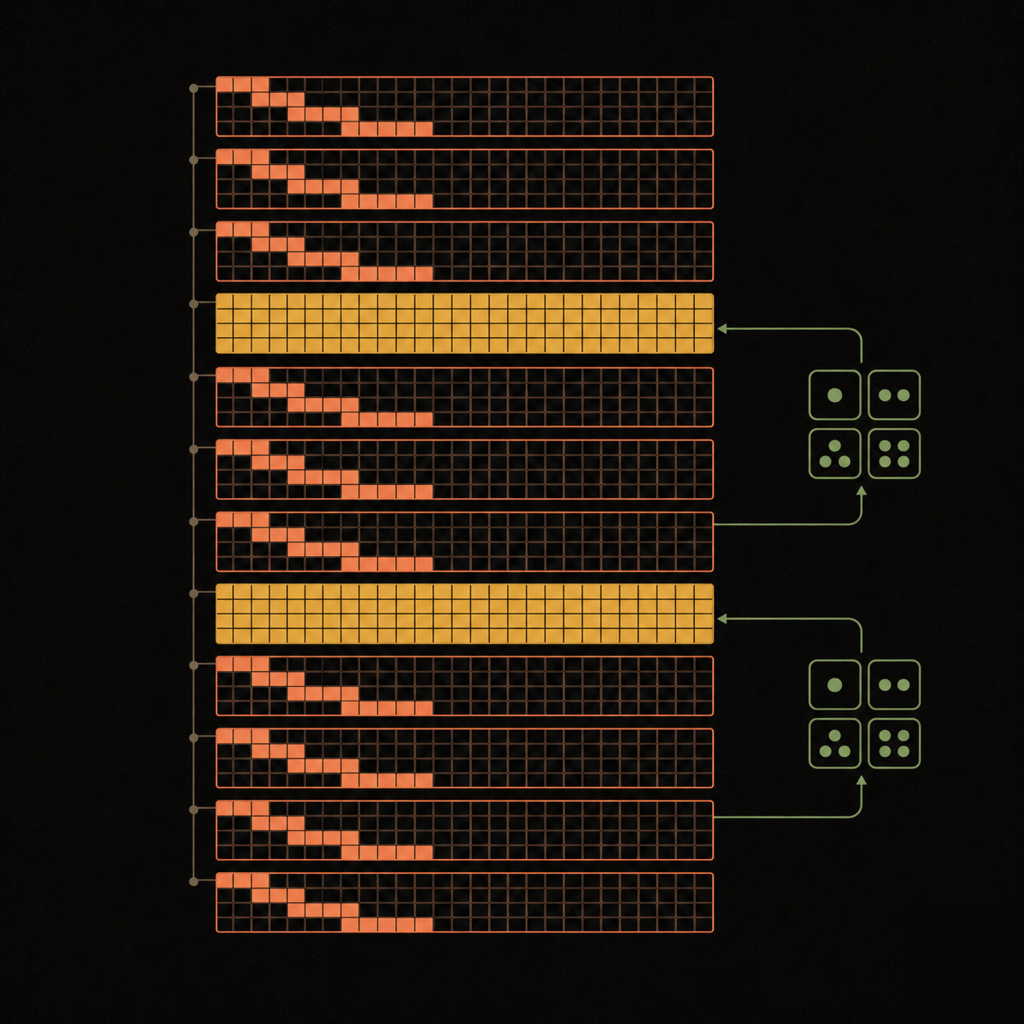 May 12, 2026
May 12, 2026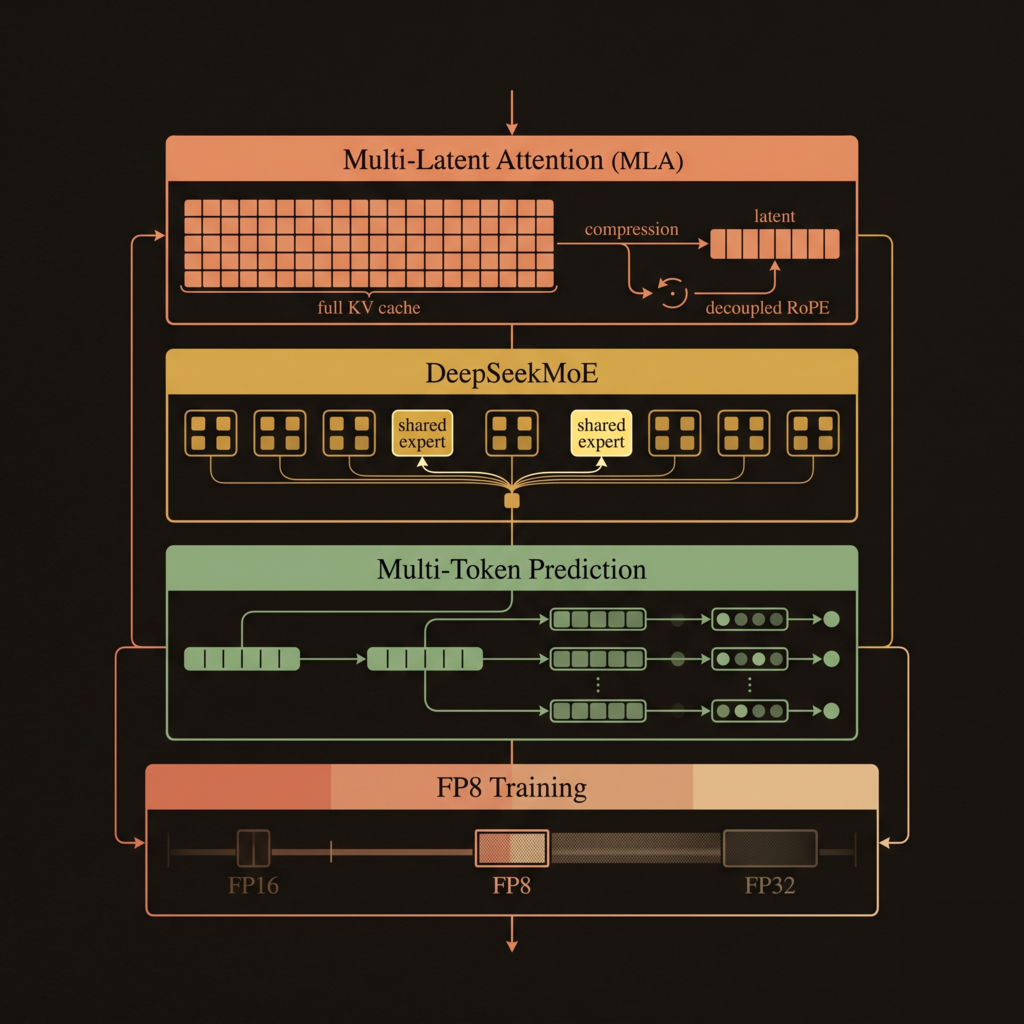 February 12, 2022
February 12, 2022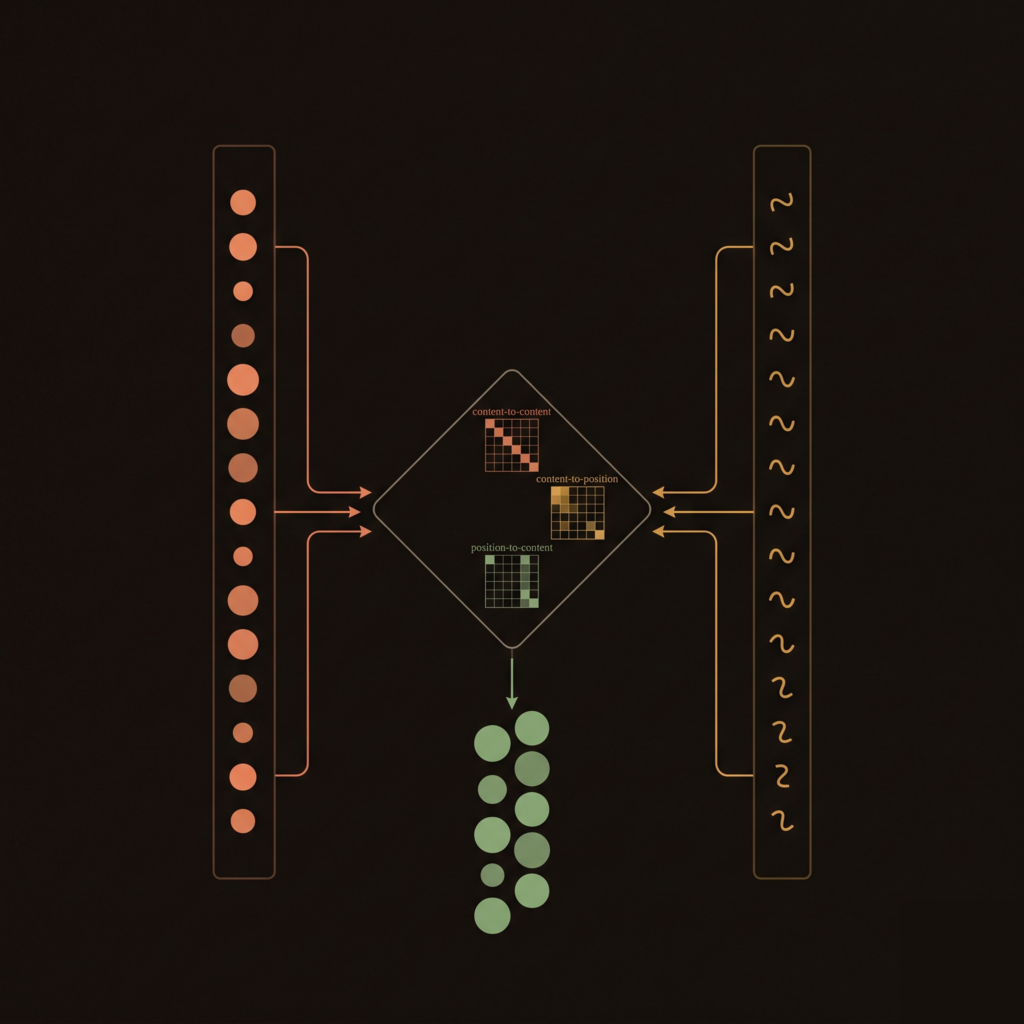 February 12, 2022
February 12, 2022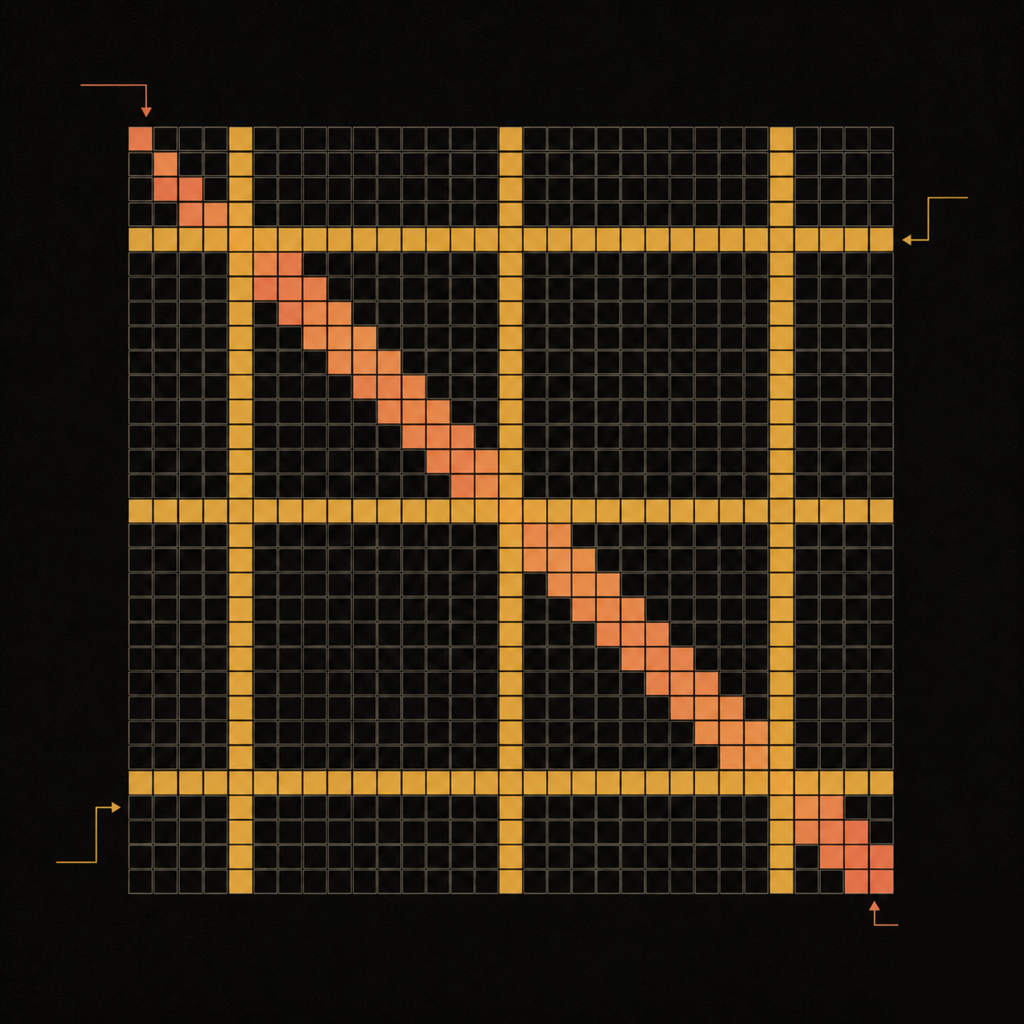
Dissecting Gemma 4: Architecture from the Ground Up
Five local layers, then one global. The hybrid rhythm.
Building DeepSeek-V3 from Ground Up
The Innovations in the Modern LLM
DeBERTa is the New King
What if attention separated content from position?
LongFormer: The Long Document Transformer
Attention as a mostly-empty matrix.