DeBERTa is the New King
NLP's state completely changed when in 2018, researchers from Google open-sourced BERT (Bi-Directional Encoder Representation From Transformers). The whole idea of going from a sequence-to-sequence transformer model to self-supervised training of just the encoder representation which can be used for downstream tasks such as classification was just mind-blowing. Ever since that day efforts have been made to improve such encoder-based models in different ways so as to do better on NLP benchmarks. In 2019, FacebookAI open-sourced RoBERTa which has been ruling as a best performer for all tasks until now, but now the throne seems to be shifting towards the new king DeBERTa released by Microsoft Research in 2022. DeBERTa-v3 has beaten RoBERTa by big margins not only in the recent NLP Kaggle competitions but also on big NLP benchmarks.
Introduction
In this article, we will deep dive the DeBERTa paper by Pengcheng He et al., 2020 and see how it improves over the SOTA BERT and RoBERTa. We will also explore the results and techniques to use the model efficiently for downstream tasks.
DeBERTa gets its name from the two novel techniques it introduces, through which it claims to improve over BERT and RoBERTa:
- Disentangled Attention Mechanism
- Enhanced Mask Decoder
Decoding-enhanced BERT with disentangled attention (DeBERTa)
Now to understand the above techniques, the first step is to understand how RoBERTa and other encoder-type networks work. Let's call this context and discuss it in the next section.
Getting Some Context
In this section we will discuss the working and flow of three key techniques that Transformer-based models introduced.
Positional Encoding
A Transformer-based model is composed of stacked Transformer Encoder Blocks. Each Block contains a multi-head self-attention layer followed by a fully connected positional feed-forward network. Introduction of feed-forward neural networks instead of sequential RNNs allowed for parallel execution of the model, but since they are not sequential, they were not able to incorporate the positional information of words (i.e., which word belonged to which position). In order to tackle this, the authors introduced the concept of Positional Encodings wherein they introduced positional vectors in addition to the word vectors and added them together to get the final vector representation for every word. Let us understand this through an example shown in the figure below.
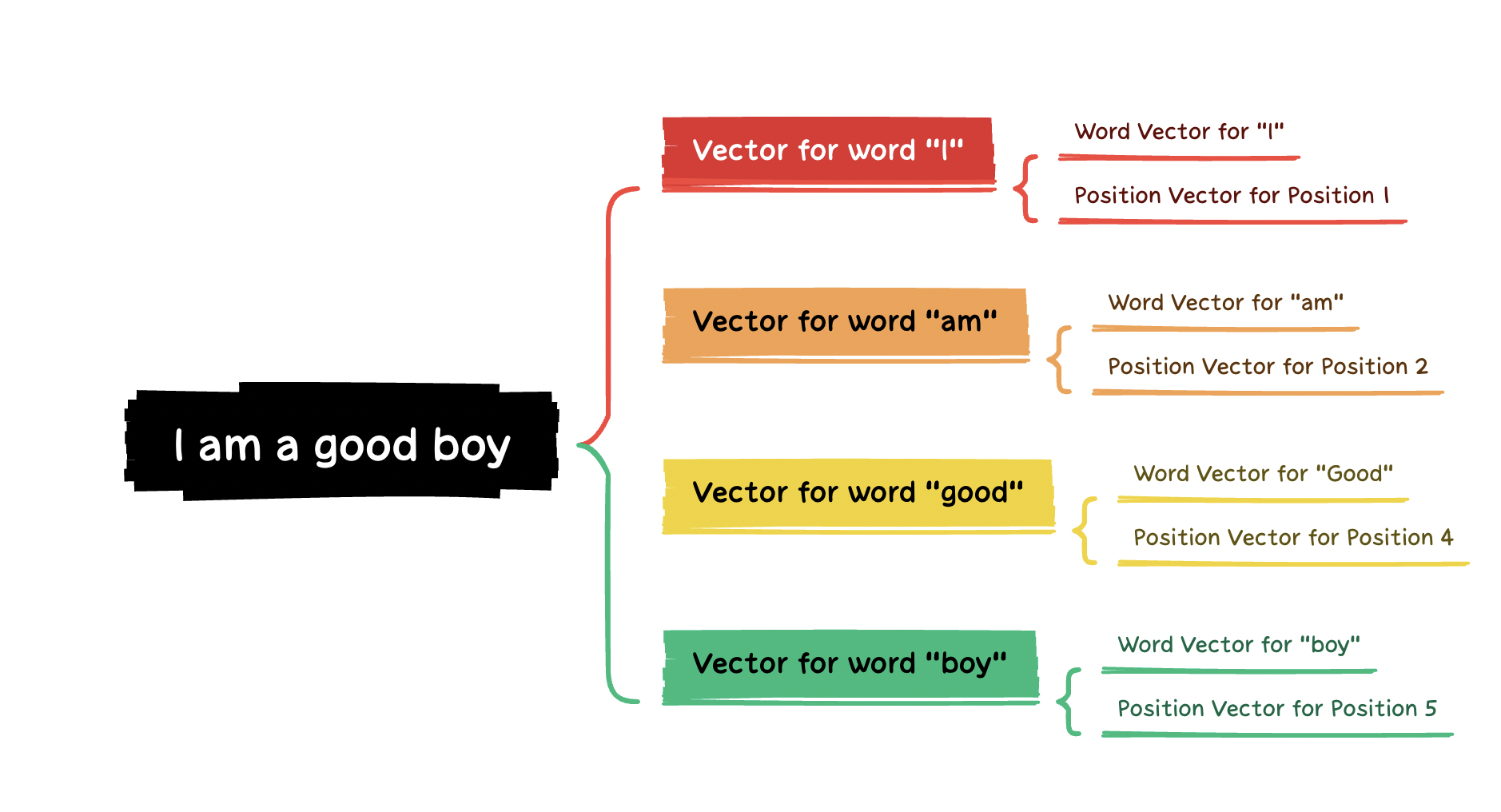 Figure 1: Embedding in Transformers
Figure 1: Embedding in Transformers
In our example sentence "I am a good boy", we assume the tokenisation to take place at word level for simplicity sake. So after tokenisation we will have the tokens as [ I, am, a, good, boy ] and their respective positions as [1, 2, 3, 4, 5]. Now before sending out the tokens into the transformer we convert them into vectors of certain dimension like we did for LSTMs, but here the vector for each token is a sum of its word vector and position vector, so for token "I" the final vector will be (word_vector_of_i + position_vector_of_position_one) and similarly for all other tokens. Now the obtained vector is represented by a vector whose value depends on its content and position. Then the transformer while training is able to understand the position of the word by certain series of activations.
In the DeBERTa paper, the authors argue that adding position embedding and word embedding together is not ideal because the positions are too much mixed with the signal of the content of the word. Thus it introduces a noise which leads to a lower performance and hence they propose Disentangled Attention mechanism in which they use two separate vectors for content and position and calculate attention using disentangled matrices using both vectors.
Multi-Headed Self Attention
A standard self-attention works by computing for every word from the input text an attention weight which gauges the influence each word has on another word. This attention mechanism uses an embedding vector which has position and context information mixed together which helps in understanding the absolute positions of the words. Each of the tokens in the input text produce Query(Qi's) and Key (Ki's) vectors, whose inner product then results in Attention Vector (Ai's). When we combine all queries and keys we get the Query Matrix and the Key matrix, their inner product gives us the attention matrix, where in the Attention matrix represents the attention weight of on which gauges the influence of on .
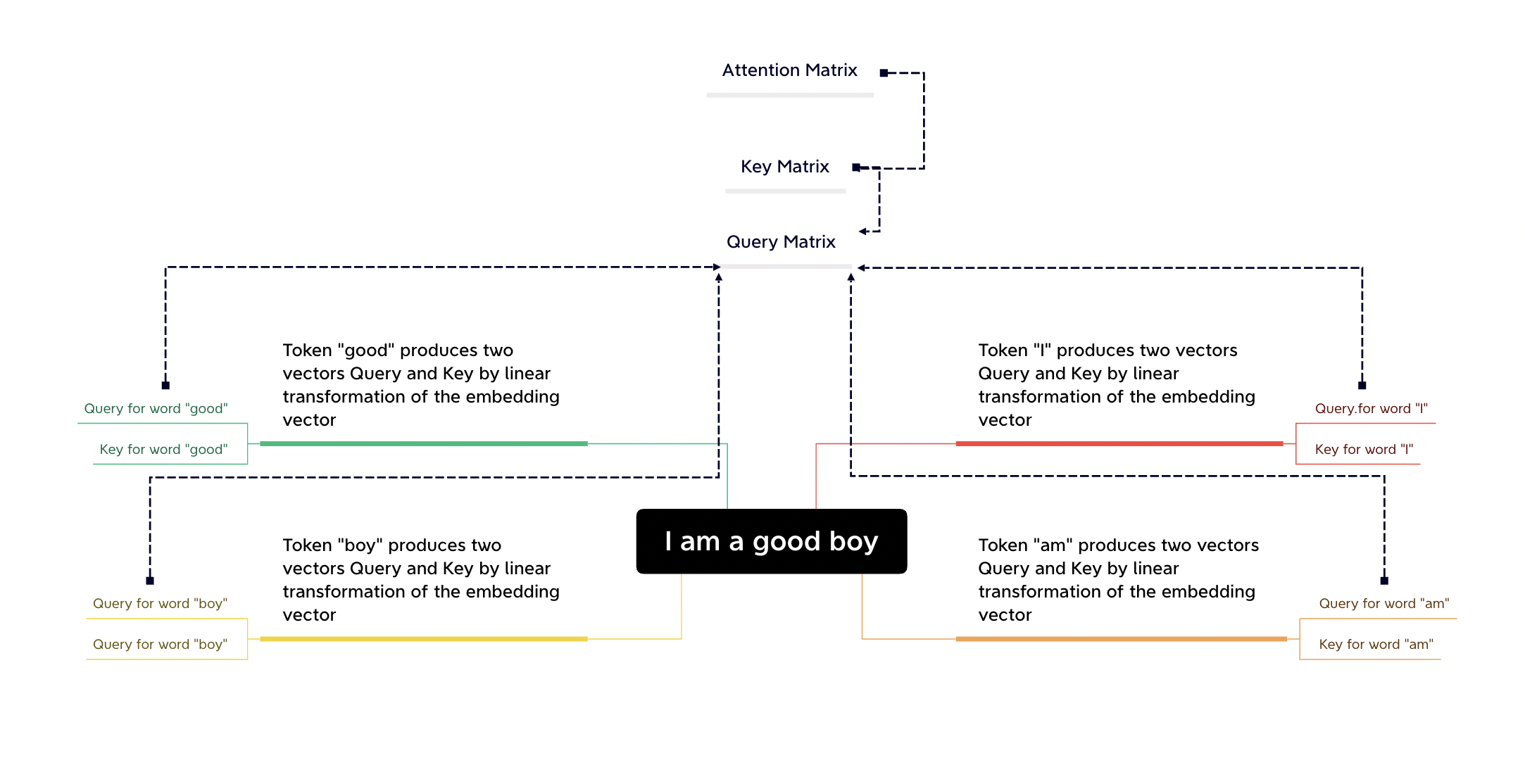 Multi-Headed Self Attention
Multi-Headed Self Attention
However the self-attention is not capable of naturally gauging the relative positions of the words. This is where the positional encoding comes in. Then we have multiple heads instead of a single head doing the same thing but on different parts of the embeddings thereby allowing for learning of different representations of the same word.
In the DeBERTa paper, the authors claim that this is also not ideal and both positions and contents should have separate signals.
Masked Language Based Self-Supervised PreTraining
With the BERT paper, authors came out with a self-supervised pre-training technique that revolutionized NLP. They showed that a transformer model's encoder can be trained using a Masked Language Modelling Objective (an objective where 15 percent of the tokens in an input sentence are masked and the model has to predict the masked tokens) and Next Sentence Prediction to incorporate the knowledge of a Language, and that pretrained model can be used for downstream tasks for that Language.
The Components of DeBERTa
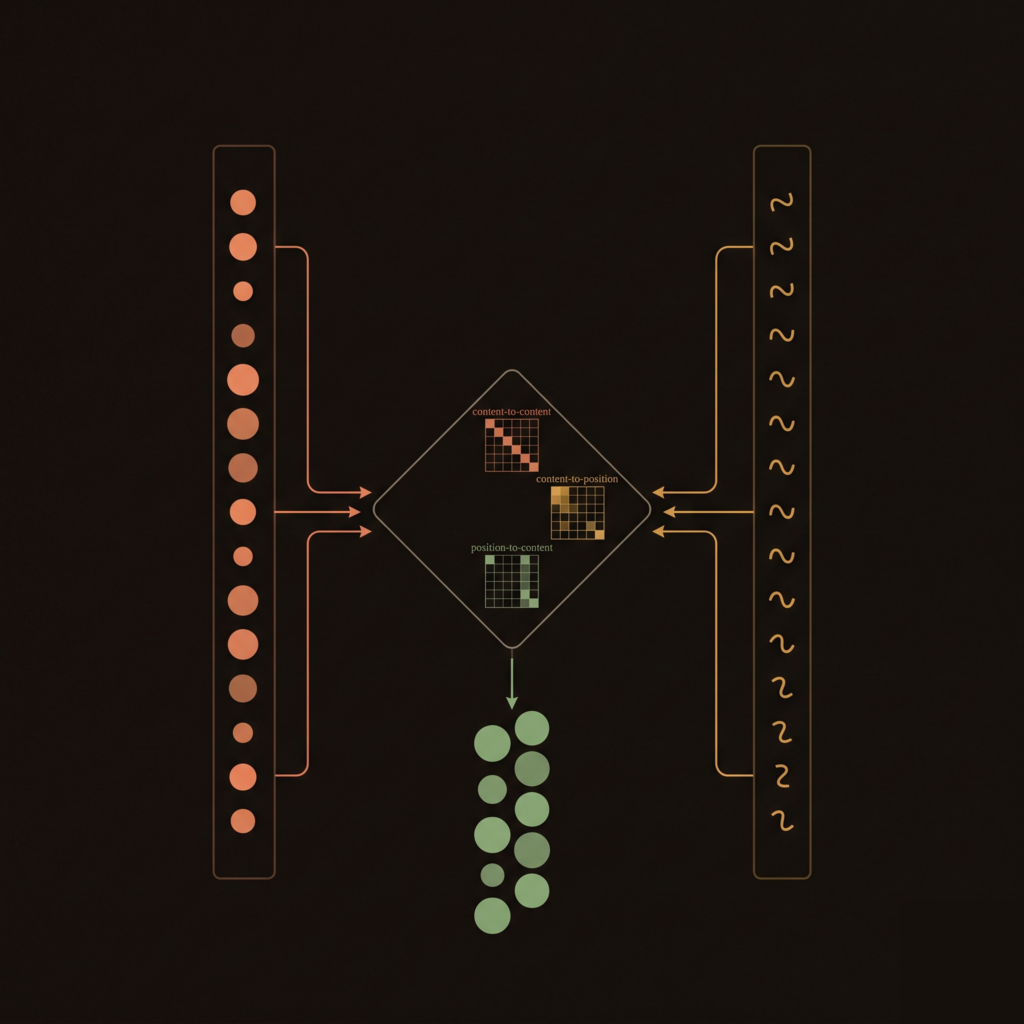
 DeBERTa Attention Mechanism
DeBERTa Attention Mechanism
Now that we have context of how the competitors work and their shortcomings, we can dive deep into how DeBERTa works and improves upon its predecessors.
Disentangled Attention Mechanism
Unlike BERT where each word in the input layer is represented using a vector which is the sum of its word embedding and position embedding, in DeBERTa each word is represented using two vectors that encode its content and position respectively. The attention weights among words are computed using disentangled matrices. This is motivated by the observation that the attention weight of a word pair not only depends on their contents but their relative positions as well.
In BERT as explained above, every token produced a single Query and a Key vector and their inner product gave us the attention weights. Since every token there was represented by a single vector (H) the equation looked like:
where H represents the Hidden state or the embedding matrix for the whole input, represents a linear projection matrix for Query and Key respectively, represents the Attention Matrix and the output of self-attention.
In DeBERTa, for a token at position in a sequence, it is represented using two vectors, and , which represent its content and its relative position with respect to the token . Let's go back to our example in order to understand this better. In our example "I am a good boy", if we have to calculate how ("am") attends to ("boy"), we will first get two vectors from : (word Vector for "am") and (because Relative Position Vector of token Position 2 with respect to Position 5 is +3). Let's look at the picture below to understand better.
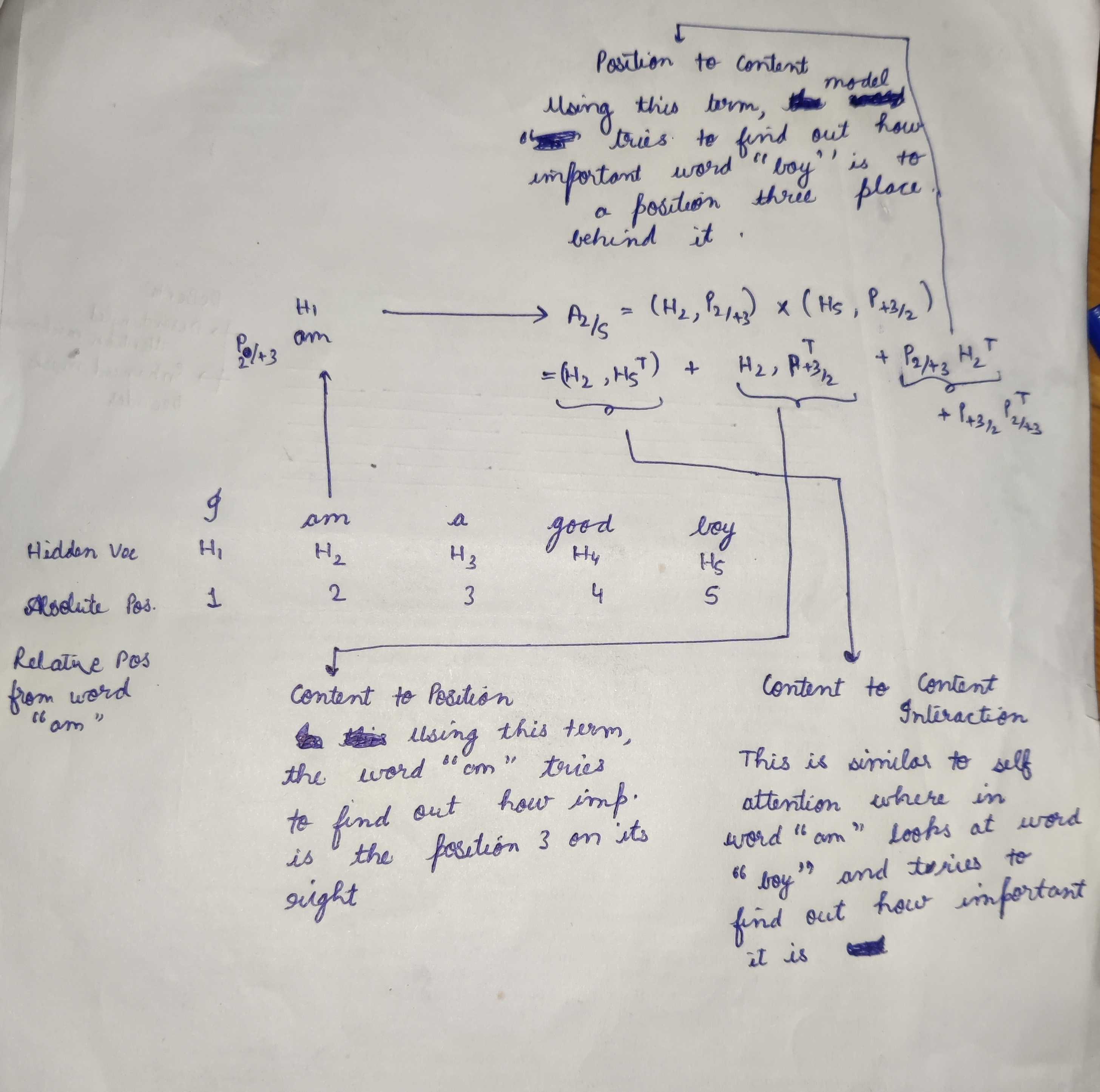 Disentangled Attention Example
Disentangled Attention Example
General Equation:
where is the Attention weight for when looking from .
This new Disentangled Attention is a sum of four components whereas previously in BERT and RoBERTa it used to be a single term . Thus this mechanism is able to capture much more information than the standard self-attention. Let's look at the components:
- Content to Content
- Content to Position
- Position to Content
- Position to Position
Content to Content is similar to standard self-attention, where each word looks at all the different words in the input text and tries to gauge its importance on itself.
Content to Position term can be interpreted as ("am" in our case) trying to find out which position around it is important to look at and from which position around it should request more information than others. For example: Let's say the model has figured out already that "I" should come before "am", thus now for token "am", the information about "I" is not much useful now. Using this term in attention, the word "am" can decide: since I already know the word before me will be "I", I want to look at the words after myself.
Position to Content term can be interpreted as saying: I am at position , which words should I look at in the input sentence w.r.t. this position so that I can be better at predicting masked tokens.
Position to Position term is not that useful because we are talking about relative positions.
One thing to note here is that while the hidden layer embeddings change every layer, the relative positional embeddings remain the same and are taken the same at every layer. Also the Relative Positions are clipped and only exist till ±k w.r.t. some position.
Thus in this way, by feeding in relative position information at each step and keeping it separate from context information, DeBERTa is able to gather more information about the words as well as their relative positions.
Enhanced Mask Decoding
DeBERTa is pretrained using MLM similar to RoBERTa and BERT, where a model is trained to predict the randomly masked words in a sentence using the context from surrounding words. Since DeBERTa uses relative positions instead of Absolute positions of words, it is not able to efficiently transfer the context for the masked word prediction in some cases. For example: Given a sentence "a new store opened beside the new mall" with the words "store" and "mall" masked for prediction. Using only the local context (e.g., relative positions and surrounding words) is insufficient for the model to distinguish between store and mall in this sentence, since both follow the word "new" with the same relative positions, thus giving the same context information about two different words. To address this limitation, the model needs to take into account the absolute positions in addition to the relative positions. In order to do that, the absolute position information is added right after the transformer layers just before the softmax layer for masked token predictions. This is what they call Enhanced Mask Decoding. The authors argue that in this way DeBERTa captures the relative positions in all the Transformer layers and only uses absolute positions as complementary information when decoding masked words. They also compare EMD with BERT's architecture (where absolute positions are input at the first layer only) and observe that EMD works much better. They conjecture that the early incorporation of absolute positions used by BERT might undesirably hamper the model from learning sufficient information of relative positions.
Scale Invariant FineTuning
In addition to some major component changes, DeBERTa authors also pretrain the model using a new adversarial training algorithm, Scale Invariant FineTuning (SiFT).
Virtual Adversarial Training is a regularization method for improving models' generalization. It does so by improving a model's robustness to adversarial examples (examples which are completely different from training distribution) which are created by making small perturbations to the input. The model is regularized so that when given a task-specific example the model produces the same output distribution as it produces on an adversarial perturbation of that example.
The authors propose SiFT that improves the training stability by applying the perturbations to the normalized word embeddings. Specifically when fine-tuning DeBERTa to a downstream NLP task, SiFT first normalizes the word embedding vectors into stochastic vectors and then applies the perturbations to the normalized embedding vectors. This substantially improves the performance of the fine-tuned models.
Conclusion
This paper presents a new Transformer-Based Architecture, DeBERTa, which introduces two novel parts that help to significantly improve over RoBERTa and BERT on almost every NLP task. DeBERTa has seen rising popularity and new versions applying different pretraining techniques have been released by Microsoft as well. DeBERTa surpassing human performance on SuperGLUE marks an important milestone toward General AI, with much more improvements to come.
I tried to explain the components in as easy terms as possible. If you have enjoyed the blog, I recommend reading the original paper.