Building DeepSeek-V3 from Ground Up
Part of the Paper × Code series — where we dissect papers and rebuild them from scratch.
Coming Soon. This post is currently being written. Check back soon for the full paper dissection with code implementations.
What We're Building
Paper: DeepSeek-V3: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Authors: DeepSeek-AI (December 2024)
Link: arxiv.org/abs/2412.19437
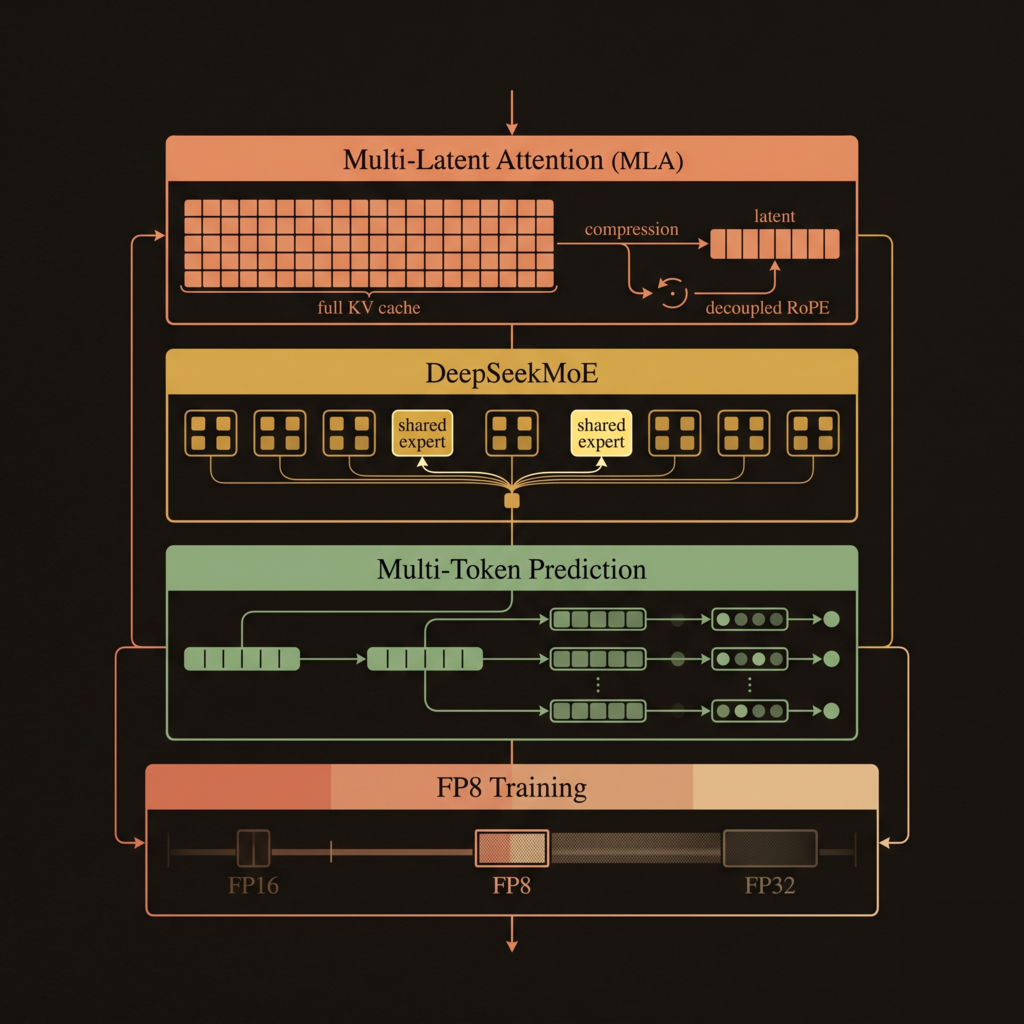
The architecture at a glance:
- 671B total parameters, 37B active per token
- Multi-Latent Attention (MLA) — compressed KV cache with absorbed projections
- DeepSeekMoE — fine-grained experts with auxiliary-loss-free load balancing
- Multi-Token Prediction (MTP) — predicting multiple future tokens per position
- FP8 mixed-precision training
We'll build each piece, understand why it exists, and see how they compose into the full model.
Part 1: Multi-Latent Attention (MLA)
The Compression Pathway
TODO: Joint KV compression into latent c_t. W_DKV down-projection. Why joint (not separate K, V compression).
The Absorption Trick — Full Derivation
TODO: Complete math showing how W_UK absorbs into W_Q. Dimensions at each step.
The RoPE Problem
TODO: Why RoPE breaks absorption. Position-dependent rotation applied after projection means c_t can't carry position info through the absorbed path.
Decoupled RoPE Design
TODO: The two-pathway solution. Content keys (from latent, absorbed) + RoPE keys (small, cached separately). How the attention score combines both.
Code: MLA Layer
TODO: Full PyTorch implementation with comments.
Part 2: DeepSeekMoE
Why Fine-Grained Experts?
TODO: The argument for many small experts over few large ones. Combinatorial flexibility.
Shared Experts + Routed Experts
TODO: Always-active shared experts provide baseline capability. Top-k routed experts provide specialization.
Auxiliary-Loss-Free Load Balancing
TODO: The problem with auxiliary losses (they hurt model quality). DeepSeek's bias-term approach. Dynamic adjustment.
Code: MoE Layer with Routing
TODO: Full PyTorch implementation — router, expert dispatch, load balancing.
Part 3: Multi-Token Prediction (MTP)
The Idea
TODO: Predicting multiple future tokens per position during training. How it provides richer training signal.
Architecture for MTP
TODO: The sequential prediction modules. How they share the main model's representations.
MTP as Speculative Decoding
TODO: How MTP heads double as draft models during inference for free speculative decoding.
Code: MTP Head
TODO: Implementation of the MTP training and inference logic.
Part 4: FP8 Mixed-Precision Training
Why FP8?
TODO: The memory and compute savings. Why DeepSeek went here when most were still on BF16.
The Fine-Grained Quantization Strategy
TODO: Tile-wise scaling, which operations stay in higher precision, handling of outliers.
Code: FP8 Training Utilities
TODO: Key quantization and dequantization routines.
Part 5: Putting It All Together
The Full Model Architecture
TODO: How MLA + MoE + MTP compose. The full forward pass.
Training Infrastructure
TODO: 2048 H800 GPUs, pipeline parallelism, expert parallelism, DualPipe.
The Results
TODO: Benchmark comparisons, serving efficiency numbers, cost analysis.
Key Takeaways
TODO: What practitioners should take away. What's reusable at smaller scales. What requires DeepSeek-level resources.